Thinking Outside the Box: Spatial Anticipation of Semantic Categories
Martin Garbade and Juergen Gall
Abstract
For certain applications like autonomous systems it is insufficient to interpret only the observed data. Instead, objects or other semantic categories, which are close but outside the field of view, need to be anticipated as well. In this work, we propose an approach for anticipating the semantic categories that surround the scene captured by a camera sensor. This task goes beyond current semantic labeling tasks since it requires to extrapolate a given semantic segmentation. Using the challenging Cityscapes dataset, we demonstrate how current deep learning architectures are able to learn this extrapolation from data. Moreover, we introduce a new loss function that prioritizes on predicting multiple labels that are likely to occur in the near surrounding of an image.
Images
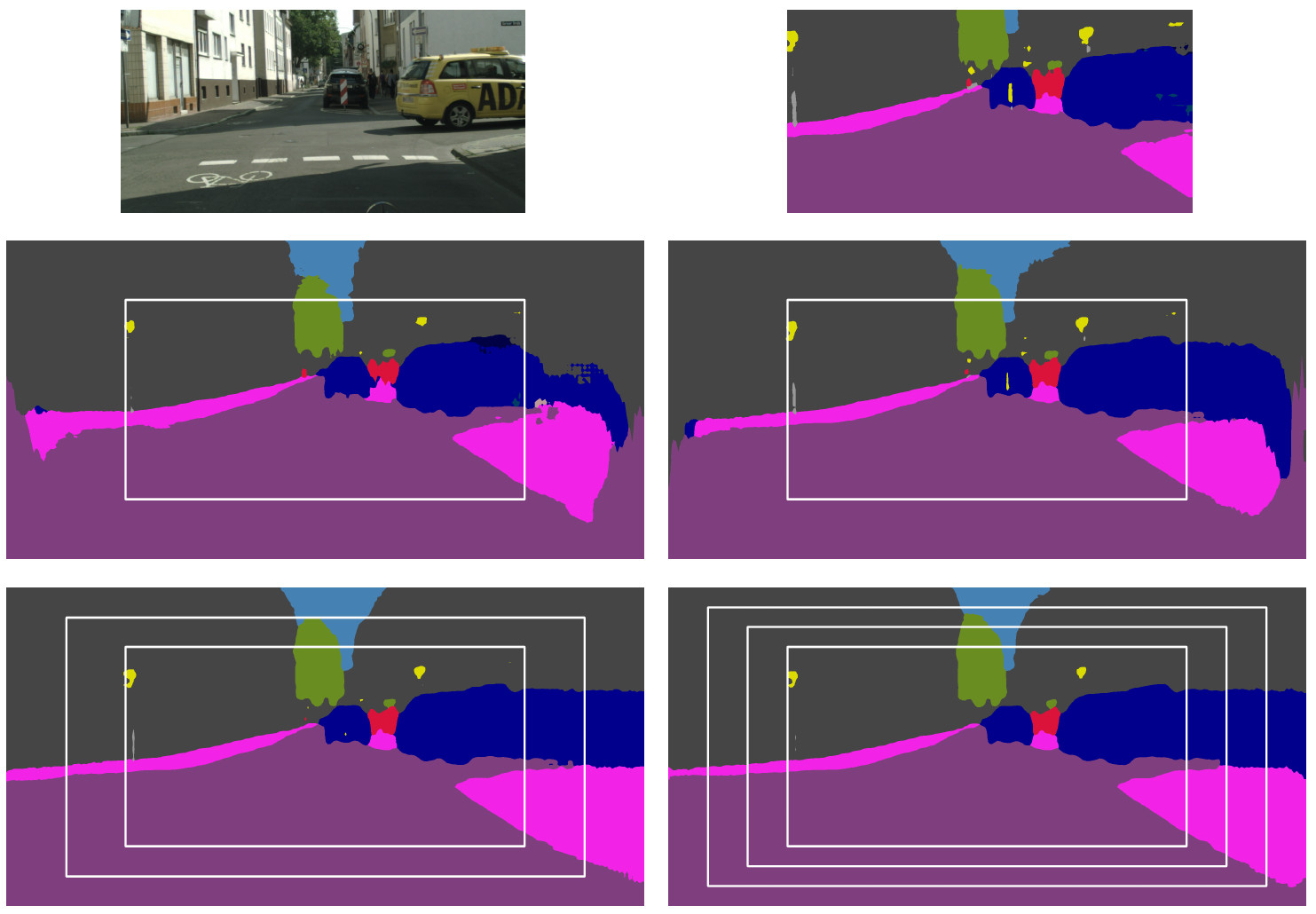
Qualitative results for the pixel-wise label prediction. The first row shows an RGB image and the inferred semantic segmentation. The second row shows the result for color-SASNet (left), which uses the RGB image of the first row as input, and for label-SASNet (right), which uses the inferred labels as input. The inner white rectangle marks the boundary between observed and unobserved regions. The label-SASNet anticipates the semantic labels better than color-SASNet. The last row shows the result of label-SASNet if the prediction is performed in two (left) or three steps (right). The additional white rectangles mark the growing regions that are predicted in each step. Compared to the second row, the labels are better anticipated at the border.
Data/Source Code
If you have questions concerning the data or source code, please contact Martin Garbade.
Publications
Garbade M. and Gall J., Thinking Outside the Box: Spatial Anticipation of Semantic Categories (PDF), British Machine Vision Conference (BMVC'17), To appear.